Jetson Nano Kubernetes Kernel Guide
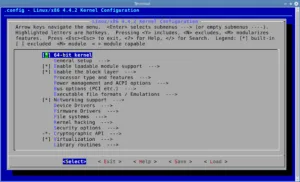
Build a Custom Kernel for Modern K8s Support 🚀 Unlock Full Kubernetes Support on Jetson Nano The NVIDIA Jetson Nano is a powerful and compact platform for AI and edge computing, but its default kernel is missing critical features required by modern Kubernetes workloads. If you’ve run into persistent kube-proxy sync errors, broken container networking, […]
Jetson Nano Kubernetes Kernel Guide Read More »



